14 de Maio de 2026 · 3 min de leitura
A Criar um Modelo de AI para Detetar Perturbações em Florestas
Em março deste ano ganhei uma bolsa de investigação para criar modelos de AI para detetar perturbações em florestas na União Europeia, mas mais especificamente, na zona mediterrânea. Uma vez que isto é algo que irei estar a trabalhar durante, no mínimo, mais um ano, muito irá mudar, no entanto, uma vez que já estou dentro do projeto decidi escrever um pouco sobre o progresso.
O grande problema hoje em dia, é que sabemos que existem perturbações a nível da floresta Europeia devido a alterações climáticas, mas estas são difíceis de quantificar e localizar. Até hoje, existem poucos modelos em que podes deixar a correr e que te identifique não só as zonas perturbadas, mas também o tipo de perturbação. E portanto, Portugal, em colaboração com Espanha, Itália e Grécia, estão a unir forças e a tentar tornar isto uma realidade para a zona mediterrânea inteira. Eu estou para além de feliz por estar envolvido em algo tão fascinante e que poderá trazer tanto para o futuro do estudo de perturbações florestais, alias, sendo honesto, eu ainda não acredito que aqui estou.
Este projeto é bastante complexo, como é de esperar, e existem cerca de 5 grandes "capítulos". Neste momento ainda estamos no primeiro, portanto isto é algo que vai demorar algum tempo. O trabalho que estou a fazer agora é essencialmente construir o dataset para treinar o modelo, e encontra-se na transição da arquitetura V1 para a V2 do capítulo 1. Passo a explicar,
Para treinar qualquer modelo de AI precisamos de um dataset de treino e validação. A ideia da equipa era criar o maior dataset possível, o mais eficientemente possível. Mas... como é que sequer começamos a criar este dataset? Vamos ao Google Earth e simplesmente tentamos, a partir das imagens históricas, encontrar cortes-rasos, incêndios, pestes e outras perturbações? Não. Íamos perder 10 anos no processo. Portanto, a equipa está a usar um novo algoritmo de ML não supervisionado (chamado 3I3D) que automaticamente, baseado em índices de vegetação, identifica perturbações florestais com um nível de precisão aceitável. Acelarando-nos a criação do dataset por umas boas ordens de magnitude.
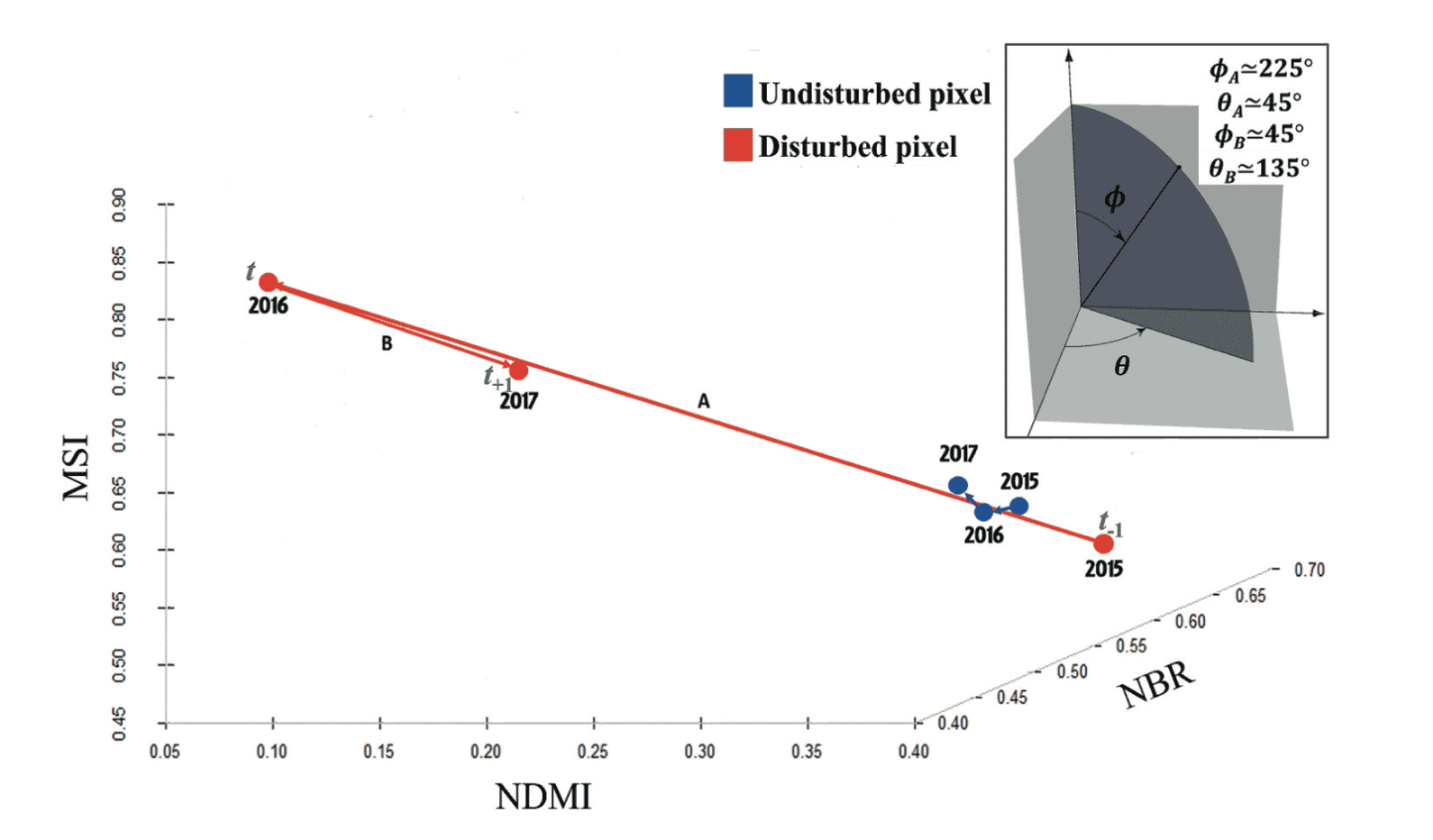
Mas isto é só parte da história, obviamente, sendo que este algoritmo apenas deteta se existe ou não perturbação, não que tipo de perturbação é. E portanto, aqui entro eu. Neste momento eu estou a ajudar a criar o dataset para treinar o grande modelo de AI/ML. O que estou a fazer chama-se fotointerpretação. Essencialmente estou a conferir os resultados do algoritmo de ML, dizendo se na verdade existe ou não uma perturbação, e, no caso de existir, que tipo de perturbação é. Isto é um processo um pouco aborrecido e extremamente sistemático, mas esta é a realidade de modelação... Criar datasets é sempre um pesadelo infelizmente.
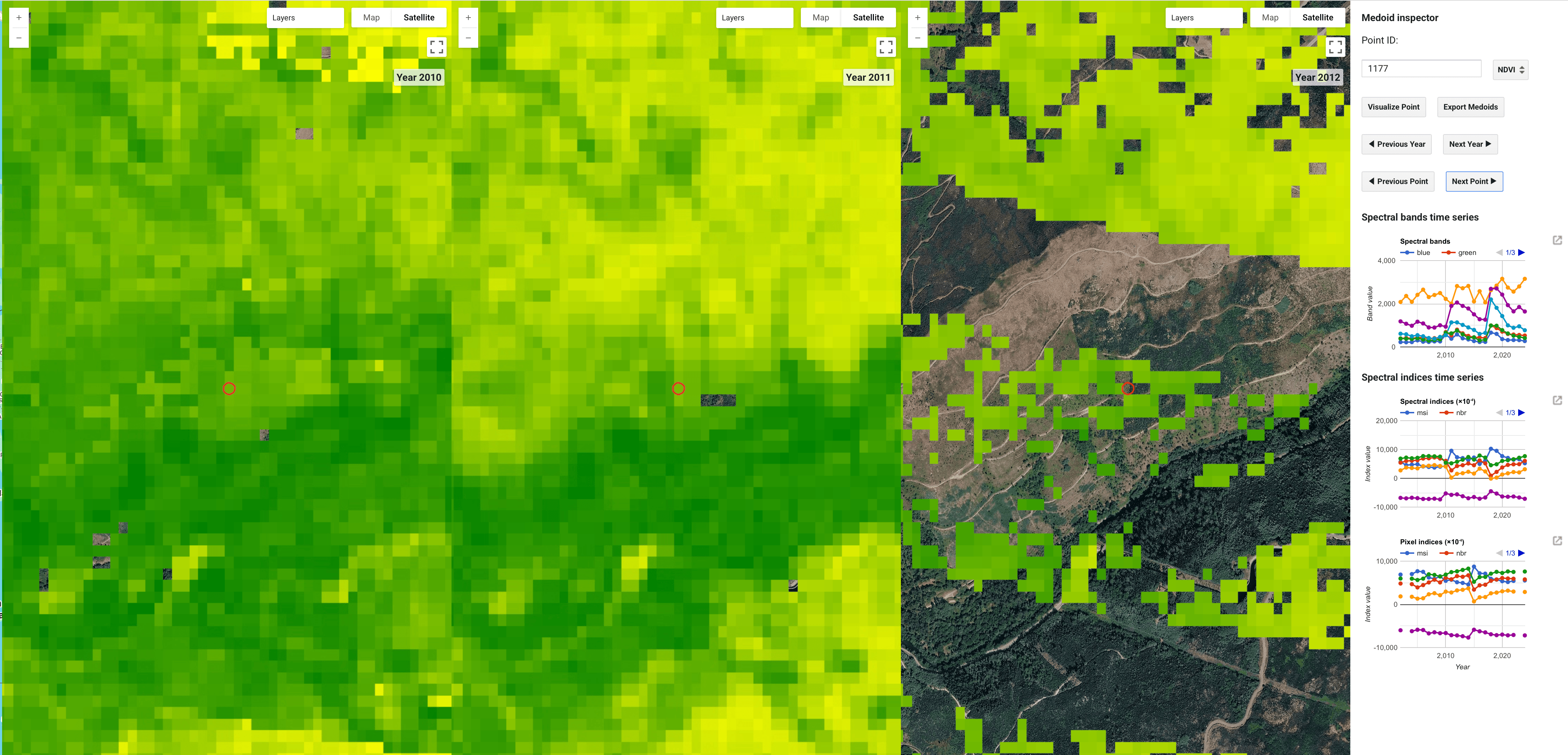
Ainda é muito cedo para dizer alguns aspetos do meu trabalho, mas é seguro dizer que daqui uns meses vou ter um extra objetivo dentro do projeto extremamente louco. Quando for altura, eu venho aqui falar mais sobre isso. Mas é sem dúvida a coisa mais importante e impactante que já fiz na vida.
Na semana passada fui ter com a equipa Espanhola para coordenarmos a nossa metodologia. Não só foi a primeira vez que saí do país, como fui sozinho! Foi uma semana super intensa em Madrid, com muito stress, mas fiquei muito feliz por ter ido e sinto-me bastante realizado.
E ao mesmo tempo que trabalho nisto, estou a fazer a minha dissertação de mestrado ao mesmo tempo. Que está também dentro da área de AI, mais especificamente, LLMs. Mas isto é outro tópico que eventualmente irei falar aqui.
Enfim, isto é apenas uma publicação para introduzir o tópico, porque eu vou ter muito mais para dizer sobre isto nos próximos meses... acreditem.
Comentários